 請自覺遵守
請自覺遵守
搬家(博客)記
太長不看:博客遷移至 https://renyuneyun.gitlab.io/ ;wikiblog廢棄;在is-programmer的博客或許仍會同步更新技術相關文章。
博客在is-programmer安家很久了,稍微一算已有八年。回頭看看,這八年我經歷了許多事情,國際互聯網也經歷了很多事情。不說其他,單單是對隱私的要求便已經比八年前強了許多。
而is-programmer平臺已經很久沒人維護了(百合仙子的這篇博文有更多一點信息),其令人擔心的有兩點:安全性和可靠性。
安全性主要是指https。因爲網站登錄需要輸入密碼,沒有加密的話很容易就會被有心人竊取到。很不幸,這個平臺的登錄並沒有自己在應用層進行加密(忽然想到了之前自己本科學校WiFi登錄的密碼是用base64轉換了一遍權當加密),所以隨便一監聽就能拿到完整的用戶名和密碼。(因而我也將我在這裏的密碼改成了一個萬一真的被他人竊取到也影響不大的。)
而對可用性的擔心則是在於萬一服務器或DNS解析停止工作(比如沒有續費),那麼該如何將自己的數據導出並搬遷到其他地方則是一個很大的問題。雖然我每次發佈新的博文後都會wget -R一遍,但由於數據不是結構化存儲的,所以對於遷移到其他平臺的方便程度還是有所擔心的。(很神奇的是,這麼多年過去了,這個網站居然還在正常工作。)
所以,在考慮一段時間以後,決定要將博客遷移,改成靜態網站。其主要因素有二:
- 靜態網站託管服務有很多,而且再度遷移的成本很低;
- 數據是純文本,放在自己手裏,可以用git之類管理,分佈式保存,基本不用擔心丟失。
在定下基調之後我就在查看各種靜態網站生成軟件。在staticgen.com的列表中看了一遍,基本都是JS的天下(還有GitHub所推的Jekyll,Ruby寫的),而恰恰我既沒學過JS又不喜歡JS(其中一部分原因是它的S),所以給我留下的可選項就不多了。簡單看過,也就剩下Hugo、Pelican等寥寥幾個可選項目。而Hugo不支持插件,所以雖然Go的效率比Python高得多而且Hugo的星更多,我也不太想選用。
之後就是對Pelican的簡單試用,但由於官方文檔和我習慣不同,未果。而這時候,正好想起來之前(按當時的視角:兩個月前)偶然發現並且在用的TiddlyWiki,於是去多方查找用TiddlyWiki做博客的可能性。幾乎順理成章地,去年(2018年)6月開始逐步嘗試將TiddlyWiki弄成博客(並且發了一篇博文記錄)。其中最主要的好處是wiki和blog的結合,並且我自己給它也直接命名爲wikiblog。然而最後,在去年秋冬之際,終於發現TiddlyWiki還是不合適(一大因素是沒有合適做博客的主題),還是需要轉向其他的靜態網站生成器。
於是又回到staticgen.com,看了一圈還是Pelican。正好當時有另一樣東西打算弄成靜態網站,索性直接上Pelican去做它。然後就是看教程、查資料,完成了基本功能,但很多地方並不明白。在向farseerfc問了一些問題以後,算是基本弄明白了插件、主題要怎麼設置(以及最坑爹的,pelicanconf.py和publishconf.py這倆!文!件!),完成了當時手上的事。但由於沒有找到合心意的主題,內心中對是否要用Pelican還是有一些猶豫。
再後來,由於一些我自己也說不清道不明的原因,決定就用Pelican了,畢竟我還是比較喜歡ReStructuredText的。雖然一些靜態博客必然會有的問題依然存在,但不影響這個方向。在斷斷續續折騰了兩個月後,最終決定就用Pelican了。但這一段時間的折騰同時讓我意識到,無論怎樣,還是不得不去做一點前端的事情,不然插件和主題都沒法定製。
前些日子終於將之前發佈在wikiblog上的文章(主要是Rust教程相關幾篇)轉移至了Pelican下,故而正式決定要將博客遷至新地址: https://renyuneyun.gitlab.io/ 。同時,之前的wikiblog也將廢棄。
但畢竟在is-programmer安家許久,告別還是要的。之後如果博客中有技術相關文章,或許也還會隨後更新/鏡像至is-programmer。
互聯(Federated)社交網絡
2019-04-08: 本文亦在我的新博客中
(本文亦在我的wikiblog中)
互聯社交網絡是除了互聯即時通信系統/IM以外的另一主要互聯系統類型。從來沒有接觸過這類系統的人可以類比互聯的效果爲:直接在新浪微博關注騰訊微博的人(而不需要去騰訊微博重新註冊賬號)。
之前在跟人介紹時,我發現有人會將互聯系統和SSO的效果搞混。事實上,兩者完全不同。仍然以上面在新浪微博S關注騰訊微博T爲例:SSO的本質仍然是在T上註冊了一個新賬戶,然後使用T上的賬戶去關注T上的另一個賬戶,而你的S賬戶上仍然是沒有對T上的關注;但互聯SNS的效果是你直接在S上關注T上的人,不需要在T上重新生成一個賬戶。如果仍然不理解,那請思考在你不登錄T時,即使你做過了“關注”,在你的S賬戶能否看到T上被你關注的人的消息。
幾大比較知名的互聯SNS系統爲:
既然叫互聯系統,每個互聯SNS之內各個不同實例/服務器間的用戶可以互操作。事實上,這些系統主要分爲兩種協議(以及HubZilla的Zot),每個協議內不同系統也可互操作。
下文將以協議爲主要線索串聯不同互聯SNS系統特點與分別、大概歷史、以及我個人對其看法。其中內容來自我對不同互聯SNS系統的瞭解(包括使用),以及背景閱讀(尤其是下文中將會經常引用其圖片的這篇文章)。
The Federation與The Fediverse
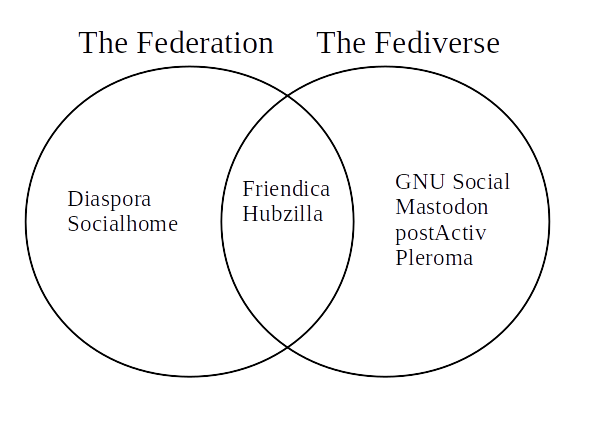 (來自https://medium.com/we-distribute/a-quick-guide-to-the-free-network-c069309f334)
(來自https://medium.com/we-distribute/a-quick-guide-to-the-free-network-c069309f334)
一般來說,在OStatus協議(及其衍生協議)下的系統(組成的網絡)被統稱爲The Fediverse;Diaspora協議下的系統(組成的網絡)被稱爲The Federation。
Federation一詞就是“聯邦”之義;Fediverse應該是Federation和Diverse(“多樣的”)兩個詞的組合。
但事實上,如圖中所示,不像商業網絡,The Fediverse和The Federation並非涇渭分明——許多系統同時支持這兩者。比如上面提到但沒有分類的Friendica就同時支持兩個網絡;HubZilla在支持自己的Zot網絡之外,也同時支持這兩者。
之所以最初有協議的分別,除了(不知道有沒有)純粹的感情因素以外,系統的目的是影響協議設計的主要區別。其中,OStatus協議設計爲微博客使用;Diaspora協議被設計來服務更偏Facebook的展板/貼子型社交網絡。於是,The Federation中系統的UI設計脫則胎於Twitter;The Fediverse中系統的UI設計則更偏向Facebook。
OStatus協議這邊稍有更多歷史可講:OStatus協議是GNU Social整合了StatusNet之後爲StatusNet協議改名的產物;而後來,Pump.io在OStatus的基礎上進行了一定改動形成了自己的協議。在2012年冬天之後,OStatus主要被一個W3C工作組維護;而後來,W3C成立了W3C Federated Social Web Working Group,並基於Pump.io的協議制定了新的ActivityPub協議,用以取代OStatus(參考自這裏)。
ActivityPub
2017年W3C將ActivityPub協議立爲推薦的標準,用來取代之前的OStatus協議。
 (仍然來自https://medium.com/we-distribute/a-quick-guide-to-the-free-network-c069309f334)
(仍然來自https://medium.com/we-distribute/a-quick-guide-to-the-free-network-c069309f334)
多數網絡均轉向支持ActivityPub協議(且許多系統已經實現ActivityPub),但Diaspora*似乎並沒有做此打算。Nextcloud這一本來並不是SNS的系統也將支持ActivityPub協議,作爲跨站/互聯消息的分發機制。
我個人是比較希望各個網絡可以整合在一個協議之下,以減少維護成本。但ActivityPub畢竟衍生自微博客協議,由於我沒有閱讀過其協議內容,所以對該協議對其他形式內容(比如版面/貼子)的支持存在疑慮。
HubZilla與Zot
HubZilla是一個比較獨特的系統:它沒有選擇使用OStatus或Diaspora協議,而是自己提出了新的Zot協議。就我個人瞭解來看,Zot並不是僅僅另一個協議:Zot最爲標彰的特點是所謂nomadic identity,這一點在其他協議(包括ActivityPub)中並不存在。
簡單來說,nomadic identity允許兩件事:
- 使用站點A的身份去登錄站點B(同樣,不需要在B上創建賬戶,數據仍然存在A上)
- 當有需要時,將站點A的身份(包括內容)整個克隆至站點B,並且所有關注了A站點身份的人將自動轉向關注站點B的身份
這兩點特性十分符合我的心意:
-
遠程認證這點省去了每次遇到新網站均需要重新註冊賬號的麻煩
- 多年來(大約四年),我一直在(時不時)尋找遠程登錄的機制,而找到的最佳機制是OpenID一類。然而,且不說我至今都沒有弄明白的OpenID版本,OpenID在多數網站上仍然被作爲一種SSO實現:之前提過,SSO本質上也是重新註冊。
-
身份的轉移則是更多考慮站點切換的問題
- 由於允許身份轉移,vender locking的情況會大大降低,迫使服務提供方不能選擇壓榨用戶
- 在特殊情況下(比如站點不再維護),身份的轉移降低了遷移成本
當然,第二條主要在沒有GDPR的時候(+的地區)比較重要——GDPR規定服務商必須允許用戶將自己的數據(用戶自己上傳/填寫的所有數據)導出成機器可讀的格式。但即使是有GDPR,用戶仍然需要想辦法手動告知其他用戶自己的遷移。
在一篇文章中,HubZilla直接被稱爲 全包平臺 ,體現了HubZilla的壯志/野心:HubZilla希望(Zot協議)成爲基礎,並且在其上構建各種服務,包括SNS、論壇、數據存儲……
我個人(四五年來)一直比較希望論壇可以被設計爲互聯系統,但一直沒有找到。HubZilla的設計給了我這個希望,且其實現已經部分涵蓋該目的。
使用體會及總結
我個人最近嘗試過Mastodon、Diaspora*、HubZilla,印象中以前也試過pump.io以及GNU Social但記憶不是很深刻。
首先,必須要強調的是,不同於舊式的中心化社交網絡,互聯社交網絡是去中心化的。去中心化帶來多種便利,但同時也可能會導致從舊時代過來的人思維遇到障礙:互聯社交網絡的“官方”只有項目網站,並沒有“官方實例”(雖然官方一般都提供實例使用,但這僅僅是諸多對等實例中的一個)。想要使用互聯社交網絡,請選擇任意一個你喜歡的實例,或是自己搭建一個實例。一般而言,官方或第三方會維護一份(到多份)實例清單(由於去中心化的本質,清單並不全面,但足夠使用),可以從中選擇一個。
基本而言,Mastodon符合其微博客服務的定位,且功能全面(內容、可見性、API及授權控制);另外其多欄的UI算是比較有特點,打破多數微博客服務那種中部瀑布的模式。另外,Mastodon似乎沒有爲動態設置地理位置的選項。
Diaspora*符合正常的以主題爲線索的社交網絡(如facebook)定位,但不包含遊戲等功能。當然,完全可以將Diaspora*當作微博客使用。
HubZilla則是一個全功能的平臺,可以當微博客、長文型社交網絡、相冊、論壇……需要注意的是,HubZilla將每一 頻道 作爲一個主體(每個賬號可以建立多個channel,彼此默認獨立),並且以頻道作爲管理單位。我也試過其nomadic identity,遷移自己的頻道並且保持聯動的更新,其效果的確符合預期。 然而HubZilla的界面看起來總有一種奇怪的簡陋感,即使其每個元素並不給人這種感覺。或許自定義主題後會有所改進,但我僅僅嘗試了默認提供的數套主題。
在測試中,每種網絡內互相關注都很輕易;跨網絡的互通測試結果如下(並沒有測試所有可能的組合):
-
HubZilla和Mastodon
-
HubZilla可以輕易關注Mastodon上的人(以
SOME_ONE@MASTODON.INSTANCE形式增加 連接 ) - Mastodon上可直接搜索HubZilla上的人(只要該HubZilla實例支持和Mastodon互聯,一般爲ActivityPub協議)
-
HubZilla上以
MASTODON.INSTANCE/SOME_ONE形式關注Mastodon上的人似乎有問題,其頭像右下角會顯示“禁止”圖標
-
HubZilla可以輕易關注Mastodon上的人(以
- HubZilla關注Daspora*上的人似乎需要對方的審覈(會在其頭像右下角顯示一個“禁止”圖標)
詳細使用體會見部分互聯社交網絡測試感受
如前面所述,整體而言,我更喜歡HubZilla的設計,於是自己在某一HubZilla實例上安了個窩。(具體地址見個人介紹頁面,這裏不再贅述;如果找不到,歡迎用你所知的任何可以聯繫我的方式詢問。)如果是爲非我自己的人推薦,Mastodon應該是我首推的,畢竟無論是功能還是設計上看我個人都很喜歡它。
Rocket使用小結
2019-04-08: 本文亦在我的新博客中
(本文亦在我的wikiblog中)
在今年Increase Rust's Reach中,我參與Rust新網站的i18n及l10n。其中新網站要基於Rocket構建,所以也就(跟着官方教程)學習了一下Rocket。 既然學了,就順便記錄一點心得和體會,以方便後來者。
Rocket是一個 web框架 。我個人對web編程(尤前端)並不太感興趣(主要是感到 web技術棧 太過麻煩/複雜),所以涉及不太多,之前也只用過Python那邊的Flask以及(一小段時間)Django以及Go自帶的http服務器,故而本文不怎麼會涉及和其他web框架的對比。
本文不打算成爲通常意義上的Rocket教程,而只是打算給有興趣者一個快速的(對rocket的)觀感。其中也會有一些個人的經驗教訓等。
Rocket概覽
類似我之前用過的框架,Rocket也將函數作爲不同的路由的處理器。Rocket在每個函數之前使用形如#[get("/myroute")]的 屬性 作爲標記,之後在Rocket入口對象/結構體上對所需要的路由(函數)進行mount即可。
#[get("/")]
fn index() -> &'static str {
"Hello, world!"
}
fn main() {
rocket::ignite()
.mount("/", routes![index])
.launch();
}
(代碼片段來自這裏。)
這點粗看很像Flask中使用@app.route()進行路由設定,僅有這兩點不同:
- Rocket不使用全局的app對象
- 路由可以定義但不掛載
我最初也以爲Rocket和Flask的設計極爲相似,且兩者都只打算做web框架而不涉及其他;然而,越到後面越是發現兩者不同之處的巨大。相對而言,我個人更喜歡Rocket的設計:更加函數導向(亦強調使用局部變量)。
-
在Rocket中,函數是處理路由的全部,不需要使用如flask中魔法一般的全局
request對象; - 函數的參數和屬性中的設定共同決定了路由是否匹配,手動類型的優勢在這裏有所體現;
- 各種(預定義或自定義的) 請求哨衛 可以被添加到函數參數表中參與決定路由的匹配性;
- 使用 整流器 在請求到達前或應答發送時對請求或應答進行調整;
-
使用
State做狀態存儲,以便的確需要“全局”變量的情況。
路由匹配
Rocket通過在屬性上設定不同的HTTP方法以及URL段來做匹配。 具體細節見官方文檔,這裏僅做摘要:
- 常見HTTP方法均被支持,只是每次只能設定一個方法
- 在未定義時,HEAD請求會被自動轉到相應的GET請求上(不過會刪除應答體)
-
表單首個字段爲
_method時,POST請求會被自動重譯爲相應的請求- 該設定是爲了方便瀏覽器,畢竟瀏覽器通常只有GET和POST
在路由的URL上,可以設定將部分(或全部) 節 注入到函數的對應參數中。Rocket會自動進行類型轉換,且僅匹配轉換成功的路由。
#[get("/hello/<name>/<age>/<cool>")]
fn hello(name: String, age: u8, cool: bool) -> String {
if cool {
format!("You're a cool {} year old, {}!", age, name)
} else {
format!("{}, we need to talk about your coolness.", name)
}
}
(代碼片段來自這裏。)
自定義類型也可用在路由匹配中,只要其實現了FromParam trait即可。
請求及應答
在不考慮整流器的情況下,用戶的請求將直接進入相應的路由函數中,然後經過函數的處理,最後函數的返回值將作爲應答。路由匹配的過程即是請求處理器的選擇過程。
Rocket不要求路由函數的返回值是一個HTTP應答(Response),而是通過Responder機制方便編程:路由函數的返回值需要是一個實現了Responder trait的類型,而Rocket負責調用Responder的相關函數將路由函數的返回值轉換爲HTTP應答。這樣,在Rocket中我們便可以用String等類型作爲函數返回值。
Rocket提供一些實現以應對常見的應答情況:
-
應答包裝器 可以包含其他
Responder,並且執行自己的修改 -
String和&str會被作爲應答體,且Content-Type會被設置爲text/plain -
Option是應答包裝器,Option<T>的T需要實現Responder:-
當是
Some時,其內容將會被作爲應答 -
當是
None時,返回404
-
當是
-
Result是應答包裝器,且其功能取決於E是否實現Responder:-
若
E實現了Responder,則該Result會被作爲應答(無論是Ok還是Err) -
若
E沒有實現Responder,則Ok會被作爲應答,但Err會被記錄在終端中且返回500
-
若
(官方文檔中還列出了幾個常見的對於HTTP很有意義的Responder實現,包括下面所說的Template。)
網頁模板
作爲一個web框架,提供對網頁模板的支持幾乎是理所應當。Rocket本身提供了Template機制,而在rocket_contrib crate中提供了一些特定模板支持。
Template被實現爲一個Responder,這樣讓響應函數返回Template類型即可:
#[get("/")]
fn index() -> Template {
let context = /* object-like value */;
Template::render("index", &context)
}
Rocket不限制使用何種模板,但官方文檔提到了.hbs Handlebars和.tera Tera。而Rocket的Template機制之所以有效,還需要整流器的幫助——所以需要在Rocket實例上.attach(Template::fairing());以便可以正確使用模板。
整流器
依Rocket文檔所說,整流器的功能類似於中間件,可以介入請求和應答過程以進行額外操作。由於我沒有學過相關課程,也沒有太多瞭解相關知識,所以無法給出個人對此的看法,只能照搬官方文檔的說法。
在類似其他框架的中間件之外,Rocket對整流器的功能有一些額外規定:
- 整流器不能終止或直接響應請求
- 整流器不能任意注入非請求數據至請求中
- 整流器可以阻止程序的啓動
- 整流器可以修改程序的配置
官方文檔對整流器有更多說明,但對我來說最需要知道的還有這些:
- 整流器應當只用於“全局”適用的東西(比如做日誌)
- 更多時候,需要的其實是 請求哨衛 和 數據哨衛
-
整流器按順序執行,所以
.attach()的順序需要注意
全局共享數據
這裏的“全局”指的是Rocket之內,在各個路由中共享數據。由於路由是由Rocket管理的,故而其參數表中沒辦法添加更多參數;而Rust又沒有全局變量(即使有也不符合美感),故而Rocket提供的 狀態 機制可謂實用非常。Rocket官方教程中也教導使用狀態來管理數據庫連接。
使用上,狀態同樣通過 請求哨衛 機制,作爲路由函數的參數。任何類型的數據均可作爲State,且不需要額外實現任何東西。唯一的要求就是在Rocket實例載入時要求管理該狀態。
像這樣要求Rocket去管理某個狀態:
struct HitCount {
count: AtomicUsize
}
rocket::ignite()
.manage(HitCount { count: AtomicUsize::new(0) });
像這樣要求在某路由函數上使用某狀態:
#[get("/count")]
fn count(hit_count: State<HitCount>) -> String {
let current_count = hit_count.count.load(Ordering::Relaxed);
format!("Number of visits: {}", current_count)
}
#[get("/state")]
fn state(hit_count: State<HitCount>, config: State<Config>) -> T { ... }
需要注意的是,Rocket對每種數據類型管理一個狀態,而不是每個數據。
另外,在自定義的 請求哨衛 中,也可以使用狀態:
fn from_request(req: &'a Request<'r>) -> request::Outcome<T, ()> {
let hit_count_state = req.guard::<State<HitCount>>()?;
let current_count = hit_count_state.count.load(Ordering::Relaxed);
...
}
(代碼片段來自這裏。)
總結
總得來說,我個人對Rocket的設計較爲欣賞/膜拜,尤其是其對Rust各項機制的有效利用。
之前用其他框架時總有覺得彆扭的地方,但它們均不存在於Rocket中,讓我寫起來覺得比較順手:
-
Django(2013年底或2014年初)
- 框架內耦合性太強,但框架的手又過長
-
什麼都想讓框架承包,初學者用起來束手束腳
- 當然,也可以說是我還沒有體會到Django的好處。但我實在是對封閉花園式的東西感到反感,所以不見得可以體會到Django的妙處
- 而且當年對Py3的支持還不怎麼樣,但我又恰恰想用Py3
-
Go(2015年)
- Go的自帶http庫直接將請求和應答對象作爲參數傳入,手動解析很難受
- Go的html模板是語言提供的,靈活度上讓我懷疑
- 當時(2015年)查過其他的go語言web框架,比較看好的有beego以及另一個想不起來名稱的。但其教程寫得並不如人意(不如我意),又由於當年需求十分簡單,所以直接裸上語言庫
-
Flask(2016年)
- Flask要使用全局的app對象和db對象,設計上很詭異
-
Flask要使用魔法一般的request對象,總讓人覺得不安心
- 且request對象暴露太多內容,類似Go用http庫的感覺(和使用Android的Context對象的感覺很像)
然而,我對Rocket的部分trait和/或類型設計仍有疑惑,還在尋找解決方案的過程中。 另外,我暫時還沒有在Rust中使用過數據庫連接,所以無法對其聯合使用後的手感做出評價。 但綜合來看,Rocket的設計可以說是我所用過的所有框架中最符合我心意的框架;而且它的設計理念可以說符合了我對web框架所構想的所有主要要求。如果不是因爲Rust仍算小衆,Rocket的用戶量和教程量應當早就超過現有的數量了吧(2018-08-02 Google搜“Rust Rocket 教程”,得到11,200條結果)。
Yu Yan Wen Zi (Chinese)
(This article is the English translation of my another post 語言文字.)
Whenever we talk about China, we usually have some thoughts about "long history", "continous civilization" or so; we are proud of this undoubtedly. The main reason we say that Chinese civilization is continous compared to other antient civilizations is that the language never cut off.
From the Seal Script to Clerical Script and from Clerical Script to Regular Script, the historians tell us the scripts/glyphs (i.e. the written part of the Chinese language) linearly derives from the same origin; although the appearance differs a lot, the Oracle Bone Script (discovered in the 20th century) still shows the same thread. After the set up of the Regular Script, the biggest change is the so-called Simplified Chinese, but it still lies in Regular Script. This is what everyone knows: we even feel our ears have been grinded to emerge cocoon. However, intentionally or unintentionally, we seem to forget that "Yu Wen" (Chinese) is "Yu Yan" (vocal form) "Wen Zi" (written form) -- except for the written part, there is still the vocal part.
Yes, the change of vocal form is harder to record compared to the written form -- there are handwrittings, records and materials and it can be written or drawn; however it's almost impossible to record the voice during the era without phonograph. The ancestors tried best only to do transliteration/transcript and/or record analogue voices -- this may be the only pity of our logogram / logographic language. Luckily, the ancient pronunciation is not entirely buried under time: phonologists figuried out some methods to try to capture the original form of the ancient pronounciations -- by using books like 《廣韻》, with the 反切 notations accummulated during history (by ancient people), and rhythmic literals like poems. My understanding towards this direction only goes as far as here, but at least I capture one important message: there are patterns and threads in the pronunciation change.
This understanding facilitates my point of view towards the present standard Chinese (i.e. Mandarin). Like what I answered in the Zhihu question《为什么角色的角念jue,却仍有人念Jiao ?》:
Instead of the view of most people that "pronunciation is always changing so there is nothing to keep an eye on", my point of view is that "some pronunciations are acceptable (i.e. follows the evolution pattern), while some are not acceptable (i.e. violates the evolution pattern and does randomly)", and I believe that "the official standard should keep a balance".
The foundation of this point of view is that: language is the tool of communications, but it is not only for the communication of people within the same era, but also across the river of time. The best choice is, apparently, to satisfy both, but if not possible, try to satisfy as much as possible and choose the one which does less "harm". However, unfortunately, people / organizations tend to, for most cases, choose to satisfy the contemporary needs -- anyway who they deal with is the people of current era, not the ancestors or descendants.
Today, when I read an article titled 《说shuō客?坐骑qí?我怕是上了个假学!》 which (again) lists what the National Language Working Commission (I used its old name, Language Reform Commission, for a derogatory sense) does to the pronunciation standards, I feel both rejoice and helpless: the LRC is still what the LRC was -- brain-damaged and doing nothing useful.
What the LRC does mostly in recent years is changing the pronuncations of some characters in Mandarin. The goal is, with no exception, to "accord with the public understanding", which simply means "if a lie is only printed often enough, it becomes a quasi-truth". This is, apparently, a method with no regards to the history, and I'm afraid it has little influence towards the communications between contenporary people. The self-learning ability of people is far better than what the bureaucrats in LRC imagine -- we can figure out and understand that two different pronunciations possibily refer to the same word, and we can "ask" even if we don't understand. If you argue that what the LRC does is to reduce the burden of students (especially those before college), this is the biggest joke of the world. There is also some (not a small portion of) people who don't possess the same pronunciation as the "standard" (because of dialect, mis-hearing, following the historical pronunciation, etc.), so there is always the need to teach about the "standard" in primary, secondary and high school; since there is the need to teach about the "standard", the effort is always needed, and time consumptions is always needed. It doesn't make any sense to consider whether there are more students or less students who need to work hard to memorize the standard (because this is not possible due to the variety).
That article specifically points out one case: some "standard" has changed from "follow the history evolution" to "accord with public" (set aside whether the sample is typical or not) and then back to "follow the history evolution". This demonstrates again that the LRC has no consensus about what the standard should be.
Of course, it seems that the article 《说shuō客?坐骑qí?我怕是上了个假学!》 possesses a ridicule attitude towards that "the public requires to keep the previous standard of the pronunciation" -- (I think) the author would either think that the pronunciation only needs to suit contemporary needs, or is just ridiculing habitually. First of all, the author seems to consider that we could only choose either to be completely unchanged or to change arbitrarily. Secondly, the author argues that the public's attitude towards pronunciation standard is "to support what fits my habit, to oppose what doesn't" -- this is shown from the fact that the author lists, for many times, how the public reacts to the "previous" change of pronunciation standard and even meaning and concludes that the public has no objection. Finally, the author seems to believe that people, i.e. the public, is only the (passive) acceptor of pronunciation standard change, and all what will be changed solely depends on the bureaucrats of LRC.
However, for all these three points, I beg to differ.
As stated previously, the choice of pronunciation should be a trade-off procedure, and it should "try to satisfy as much as possible and choose the one which does less 'harm'". The crucial point is neither to consider to change or not to change, nor to consider whom to listen to -- it is to find the balance between history (both retrospective and prospective) and contemporary era. Still, as stated above, whichever the standard is won't make a significant impact of the current era, so I believe history shoule be placed extra emphasis on. The reaction (of standard change) of contenporaries is foreseeable: some (but will never be "most", as long as the change is reasonable) people will oppose. Therefore, why doesn't the people who make the standard issue the reason at the same time? People are not idiots and we can reason about things. As long as the change is reasonable, most people will agree.
The author seems to be unaware that in some parts of the WWW, many people are discovering and researching about the original meaning of words and proper pronunciation of characters, and they spontaneously sum up the law and keep telling other people what these things should be like. Maybe the author considers the number of these people is too few, but what I saw is that the number is increasing and more and more people accepted the dissemination of the "proper". Possibily because this process moisturizes things in silence, the author may, probably, have already seen the outcomes of it, but was unaware where this came from.
Then, for the people who makes the standard, LRC as mentioned, I will sneer at them as always. If they agreed with the people's republic, instead of being sinecures, LRC should be cautious and conscientious, seek for balance between now and history, and detail that to people; if they were composed of the scholar-officials (like in the antient time), LRC should insist on the history, rather than changing back and force. Whichever form they were supposed to be, LRC didn't do the right thing, so they ought to accept my ridicule. And either in the ancient time or in mordern time, either in the East or the West, the government is supposed to listen to or be operated by the people. Now the fact that some departments of the government doesn't perform in accordance is not the reason we agree with them -- on the contrary, this is the reason that we should work harder to point out and combat.
 | Designed by
| Designed by